While deploying LogPoint with High Availability repos I did a few tests scenarios on how HA behaves that I thought would be relevant to share.
Repositories can be configured as high availability repositories which means that the data is replicated to another instance. This means that logs will be searchable in a couple of scenarios:
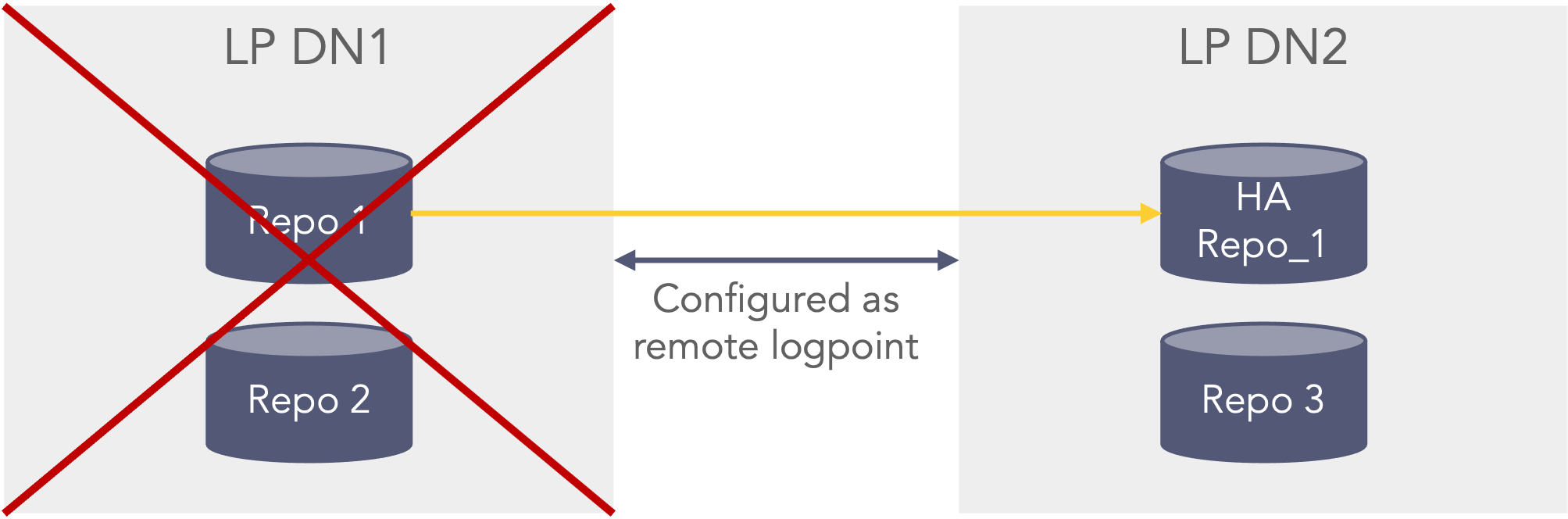
First scenario, if the repo fails on the primary datanode (LP DN1) it will be able to search in the HA Repo_1 on the secondary datanode (LP DN2). This could for instance be that the disk was faulty or removed or the permissions on the path were set incorrect. This scenario can be seen in the picture below where the Repo 1 which is configured with HA, on the primary datanode (LP DN1) is unavailable, but still searchable as the secondary data node (LP DN2) still has the data in the HA Repo 1 repo. In this scenario the Repo 2 and Repo 3 are still searchable.
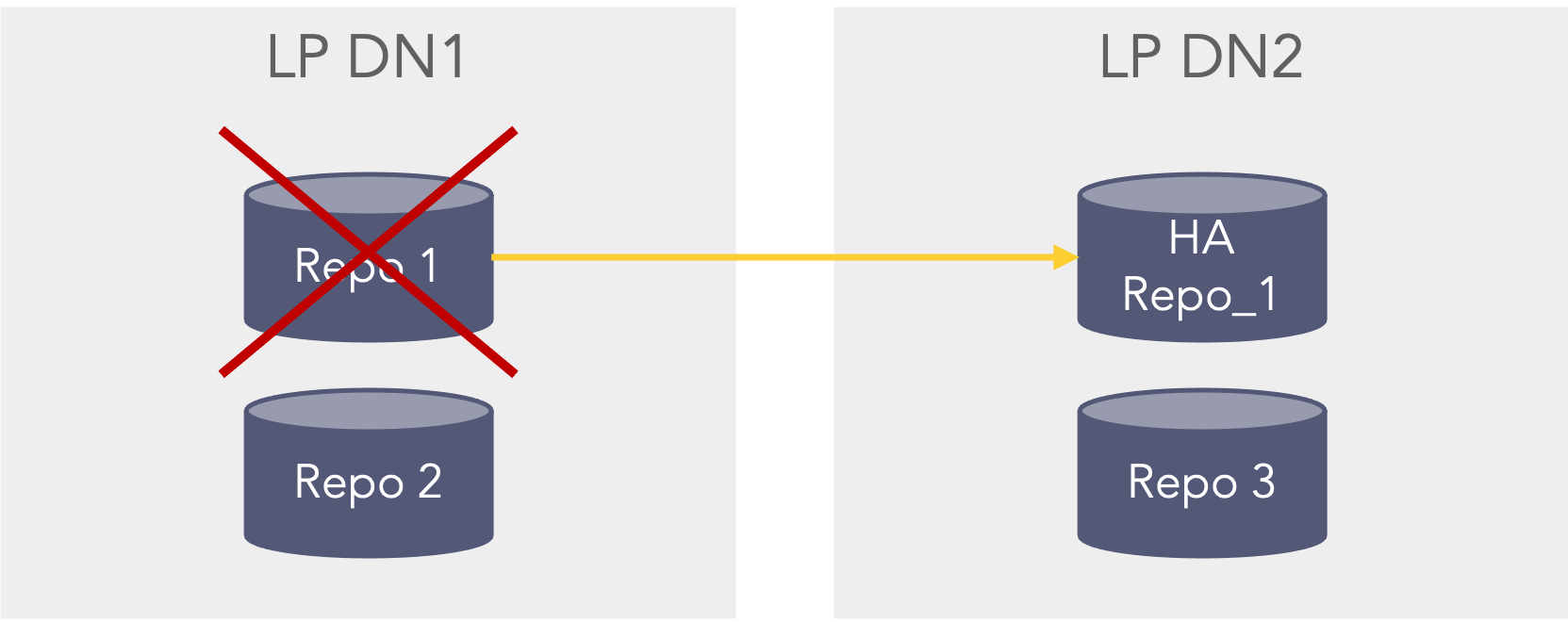
In the second scenario If the primary data node (LP DN1) is shutdown or unavailable the data can be searched from the secondary datanode (LP DN2). However, this can only happen if the primary datanode (LP DN1) is configured as a remote LogPoint on the secondary datanode (LP DN2), so that when selecting repo’s in the search bar the repo’s from the primary datanode (LP DN1) can be seen and selected when searching (This also applies before the primary datanode is down/unavailable) from the secondary data node (LP DN2). The premerger will then know that it can search on the HA repo’s stored on the secondary data node (LP DN2) even though the repo’s are down on the primary data node (LP DN1) as it cannot be reached. In this case the Repo 1 can be searched via the HA Repo 1 and the Repo 3 can also be searched, Repo 2 is not searchable.