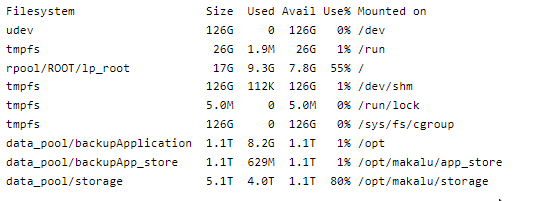
I have the problem that the storage folder is now over 90% full.
Now I wanted to empty the folder using bash commands directly in the disk notification and have applied the following to "Command:": find /opt/makalu/storage/ -type f -mtime +30 -delete
Unfortunately without success, the folder grows and grows. Do you have a tip or a solution for this?
Thank you in advance and kind regards
Page 1 / 1
Hi the way arround this is to goto your Repoes and ajust the retention perionde, that will reduce the size.
It is only run ones a day after midnight, so you will first see the result the day after.
Futher more you shouldent go over 80% then the filesystem ZFS will get slowed down witch affect server performance.
Otherwise, you are always welcome to create a support ticket via the Service Desk portal.
Best regards, Artem
Hi Artem, thanks for the article, I already know it ;-)
The only problem is, I have no access to the server and can only work directly in LogPoint.
Thanks anyway and kind regards
René
Hi Kai,
I don't think it is due to the storage time.
We have 1TB of storage and in the repo overview I see that all repos together use just about 76GB of storage.
Wouldn't it be possible to empty the folder with the commandos as soon as 90 or 80% are reached?
Thank you and kind regards
René
Well thats total storrage and now showing you the right thing.
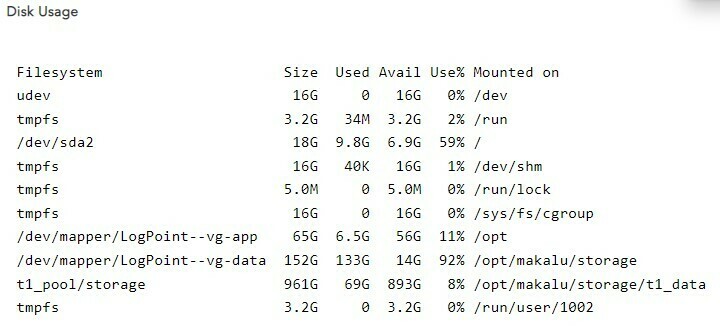
This is one of mine, but as you can see in next image I have actualy reaced the 80% on Makalu storrage.
As I’m informed, It’s now recomended to do manual deleation, I gues you can break index and its data.
It is better to let it be handled with the automated procedures for that.
-Kai
Well thats total storrage and now showing you the right thing.
This is one of mine, but as you can see in next image I have actualy reaced the 80% on Makalu storrage.
As I’m informed, It’s now recomended to do manual deleation, I gues you can break index and its data.
It is better to let it be handled with the automated procedures for that.
-Kai
Hi Kai, thanks for the info.
Here is mine:
I have now halved the retention, let's see if that helps.
Thank you and kind regards
René
Sorry dident se the 76 gb, i would do an du -sch in /opt/makalu/storage/ ad se where data are used.
No problem, there are all the time some maitance to keep system running. ;)
So i have these gauges to keep track of disk space problems
"mount_point"="/opt/makalu/storage" "object"="Hard Disk Usage" "source_name"="/opt/immune/var/log/system_metrics/system_metrics.log" | chart max(use)
Repo : _logpoint
Time 1 hour
Hello Kai,
I assume those gauges are defined on “search-head” machine. I believe DC01/DC02/DC03 are “collectors”. How did you selected the repo (into corresponding widgets) for these collectors since the “search-head” can connect only to “distributed logpoints” (and not collectors) ?
I tried the following: on “collector” I have configured the “OpenDoor”, then added the collector on “search-head” as a “distributed logpoint”. But I’ve got this message”: “10.172.182.1 is LogPoint Collector. Please remove it.”, so this method is not good.
I use LP version 7.3.1 on all instances.
You should configer “distributed logpoints” from the search head for each of your DC, and repo selcet are _Logpoint on each of them.
Does this answer your question.
-Kai
Thank you Kai for your quick answer,
In my first message I just explained that I did exactly this configuration on “search_head” and when I added the “collector” machine as “distributed logpoint” I have got the message “10.172.182.1 is LogPoint Collector. Please remove it.”
Should ignore this warning message ?
I’m not shure, the one that i have is only acting as an logpoint collector, I think you should ask Support for this question, it the easy way out and quick too.
Already a Partner or Customer? Login with your LogPoint Support credentials. Don‘t have a LogPoint Support account? Ask your local LogPoint Representative.
Only visiting? Login with LinkedIn to gain read–access.
Already a Partner or Customer? Login with your LogPoint Support credentials. Don‘t have a LogPoint Support account? Ask your local LogPoint Representative.
Only visiting? Login with LinkedIn to gain read–access.